Vortrag auf der Jahrestagung der International
TUSTEP User Group
Erfurt 12.-15. Okt. 2000 [1]
Giorgio Giacomazzi
EDV-Berater der Langzeitvorhaben der BBAW 1998-2000
Die "Langzeitvorhaben" der BBAW betreiben Grundlagenforschung im geisteswissenschaftlichen Bereich. Sie haben den Auftrag historische, literarische und philosophische Quellen zu erschließen.
Der Begriff "Word" im Titel meint nicht nur WinWord, sondern fast alle Eingabeprogramme, die in den 30 Langzeitvorhaben der BBAW verwendet werden. Dazu zählen gängige und weniger gängige Textverarbeitungs-, DTP-Programme, Datenbanksysteme. Als Eingabeinstrument wird TUSTEP nur in wenigen Fällen verwendet.
Der Vielzahl der Erfassungsprogramme und -modi, die eine große Komplexität in der Datenbeschaffenheit nach sich zieht, steht eine einzige Form der Veröffentlichung, das Buch, entgegen. Ausnahmen bestätigen die Regel.
Die Hauptfragen, die diese Situation mir zu Beginn der Beratertätigkeit 1998 aufgaben, waren:
Anfang 1998 galt SGML als die Antwort auf alle Fragen nach Mehrfachverwertung und Langzeithaltung von Daten. Mir schien SGML zwar gut geeignet zu sein für Projekte, die von Null an beginnen und mit angemessener personeller EDV-Unterstützung rechnen können, doch weniger geeignet für Vorhaben, die bereits, und zwar unter ganz anderen Prämissen, begonnen worden sind. Der Aufwand und die Risiken bei einer nachträglichen Umstellung auf SGML sind hoch und die Preise für SGML-Dienstleistungen sprechen ebenfalls für sich.
Anfang 1998 wurde aber auch XML, die "Extensible Markup Language", als Standard verabschiedet. Die Verbindung des SGML-Grundkonzepts mit der völlig neuen Möglichkeit einer stufenweisen Umsetzung in Form "wohlgeformter Daten" überzeugte und begeisterte mich sofort. Doch lagen hier noch keine Erfahrungswerte vor und es ist ohnehin schwer, Akzeptanz für ganz neue Konzepte zu finden. Daher organisierte ich neben dem Berateralltag zunächst einen internen EDV-Kreis und dann eine öffentliche Vortragsreihe über "SGML-kompatible Satzsysteme", welche durch einen grundlegenden Vortrag von Fotis Jannidis über die "Text Encoding Initiative" (TEI) eingeleitet wurde.[2] Drei Satzsysteme mit SGML-Anbindung sollten präsentiert und anhand von typischen Aufgaben aus BBAW-Vorhaben geprüft werden.
Andere Optionen schieden nach einer Vorprüfung aus. Ergebnis dieser Vortragsreihe und der im Berateralltag gesammelten Erfahrungen war 1999 der Beschluss, Pilotprojekte zur Einführung von XML in interessierte Vorhaben durchzuführen. Dabei sollten die wichtigsten Dokumentarten und EDV-Probleme behandelt werden:
Technisch gesehen sind hier vor allem die Bereiche Textverarbeitung und Datenbanken, ferner OCR und Bildverarbeitung angesprochen. Infolge des TUSTEP-Vortrags von Marc W. Küster wurde außerdem eine auf Gegenseitigkeit basierende Kooperation mit der Universität Tübingen vereinbart. Damit sagte die Uni Tübingen Unterstützung bei der Einführung von TUSTEP an der BBAW zu; im Gegenzug ermöglichte mir die BBAW die Fertigstellung eines XML-Konverters für Word in Hinblick auf dessen kommerziellen Vertrieb mit der TUSTEP-Software.
Im Laufe eines intensiven Arbeitsjahres sind in den Pilotprojekten Ergebnisse erzielt worden, die hier nur teilweise vorgestellt werden können. Ohne die Unterstützung aus Tübingen wären diese Ergebnisse, besonders was die TUSTEP-Anteile angeht, in der Kürze der Zeit nicht möglich gewesen. Für die Unterstützung und die freundschaftliche Art der Zusammenarbeit möchte ich mich hier bei der "Abteilung Literarische und Dokumentarische Datenverarbeitung" beim Rechenzentrum der Universität Tübingen ganz herzlich bedanken.
Ein chronisches Problem bei WYSIWYG-Programmen ist die Dominanz äußerlicher Formatierungen gegenüber Strukturmerkmalen, welche zur effektiven Weiterverarbeitung der Daten benötigt werden. Icons für Fett, Kursiv, Schriftarten usw. verleiten den Benutzer zu unüberlegtem Anklicken und es entsteht ein scheinbar gut aussehendes Dokument. Aber programmiertechnisch ist es schwer bis aussichtslos, Textteile mit gleicher Formatierung, z.B. Kursiv, aber unterschiedlicher Bedeutung voneinander zu unterscheiden. Da WYSIWYG-Programme nicht auf Weiterverarbeitung der Daten angelegt sind, garantieren sie auch nicht, daß die Formatierungen einheitlich kodiert sind; z.B. werden in Word 2, 6 und 95 Sonderzeichen per Menu "Einfügen-Sonderzeichen", ALT + ASCII-Code und bei Import aus anderen Programmen sehr unterschiedlich kodiert. Daher werden Word-Dokumente oft als unformatierter Text in Satzprogramme übernommen und dort anhand eines Ausdrucks noch einmal formatiert. Diese Nachformatierung bedeutet aber nicht nur Doppelaufwand, der um so größer ausfällt, je komplexer die Formatierungen sind; sie geht auch mit der Gefahr einher, daß die philologische Genauigkeit, die zuvor in jahrelanger Editionsarbeit mühsam erzielt worden ist, mangels geschulter Setzer verloren geht. Davon können Mitarbeiter der Langzeitvorhaben ein Lied singen.
Auf der anderen Seite erscheinen eindeutige Kodierungen im Klartext und deren manuelle Eingabe bei TUSTEP vielen Wissenschaftlern als schwer handhabbar und ebenfalls fehlerträchtig. Erst nach einem Satzlauf ist überhaupt eine Kontrolle möglich. Doch die wenigsten wissenschaftlichen Vorhaben verfügen über einen Setzer, der für sie eine Satzprozedur in TUSTEP realisieren und pflegen kann. Die ungewohnte Bedienung des Editor stößt gar auf erbitterten Widerstand. Das sind Gründe, warum TUSTEP trotz aller Leistungsfähigkeit sich nicht in der Breite durchgesetzt hat.
Angesichts dieser Problematik liegt es nahe die Lösung darin zu finden, die Vorteile von Word und die Vorteile von TUSTEP miteinander zu verbinden. Die Verbindung von Vorschau und Code-Ansicht begegnet auch bei HTML-Editoren und war auch in WordPerfect teilweise realisiert. Um die Anforderungen unserer Publikationsvorhaben zu erfüllen, muß aber bei allen auf dem Markt verfügbaren Programmen zusätzliche Funktionalität nachgerüstet werden; z.B. sind mehr als zwei Fußnotenreihen keine marktübliche Anforderung. Dem kommt die Programmierbarkeit von Word immerhin entgegen.
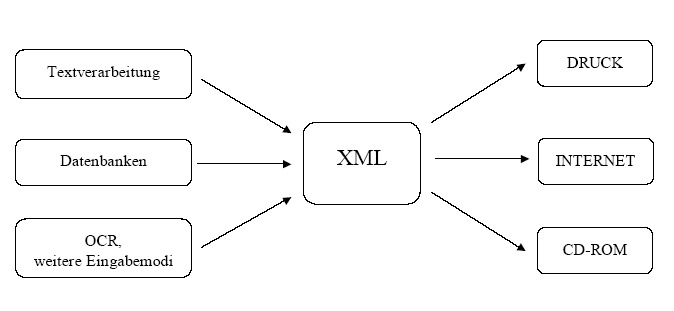
Zentrale Idee der Pilotprojekte an der BBAW ist die Schaffung von Instrumenten zur kontrollierten Texteingabe in Word und sonst eingesetzten Programmen. Soweit Formatierungen den wissenschaftlichen Informationsgehalt wiedergeben, werden projektspezifische Formatvorlagen eingesetzt. Wo Formatierungen nicht ausreichen, z.B. für Metainformationen, werden harte Kodierungen verwendet. Beides wird dann nach XML exportiert und ohne nennenswerten Aufwand von spezialisierten Programmen für Satz, Internet etc. übernommen. Dieses Gesamtkonzept geht über die skizzierte WYSIWIG-Problematik hinaus.
Abb. 1: Das Grundkonzept der Pilotprojekte
Der Ansatz der Pilotprojekte hat das Interesse der TUSTEP-Entwickler geweckt. Denn er wertet TUSTEP als Programm zur Datenverarbeitung und zum Satz auf, während er die Abhängigkeit vom Editor stark reduziert.
Eine erste Lösung dieser Art habe ich 1998 für die "Preußischen Protokolle" entwickelt; sie hat bereits zu mehreren Bänden geführt und das Interesse anderer BBAW-Vorhaben geweckt. Eine ähnliche Lösung befindet sich in der Einführungsphase bei der MGH-Stelle, eine weitere für die Schleiermacher-Edition ist in der Entwicklung.
Das Vorhaben erstellt eine Regestenedition. Ein Regest besteht aus mehreren obligatorischen und optionalen Blockelementen und aus einigen Subelementen. Entscheidend ist, daß alle diese Elemente eindeutig und konsequent ausgezeichnet werden. Dazu sieht unsere Lösung vor, daß beim Erstellen und Bearbeiten eines Regesten die Formatierleiste von Word automatisch ausgeblendet und durch eine projektspezifische Symbolleiste ersetzt wird, die nur die benötigten Formatvorlagen anbietet. Außerdem wird am Ende eines Absatzes dem folgenden automatisch die nächste Absatzformatvorlage zugewiesen: auf "Sitzung" folgt "Angaben", auf "Angaben" folgt "Anwesende" usw. Die Symbolleiste wird besonders für die Subelementen, die an beliebiger Stelle innerhalb des jeweiligen Containers vorkommen können, z.B. der Tagesordnungspunkt "TOP" und der "Autortext", ferner für Korrekturen und nachträgliche Änderungen eingesetzt. Damit ist ein kleiner SGML/XML-Editor in Word geschaffen.
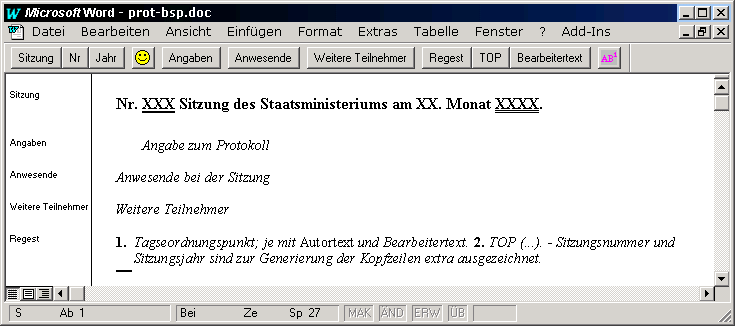
Abb. 2: Word-Umgebung der "Preußischen Protokollen"
Wenn die Daten mittels Word-Formatvorlagen eine klare Struktur haben, geht es darum, die Strukturinformationen zu exportieren und den nachfolgenden Programmen zur Verfügung zu stellen.
Dazu verwende ich ein Word-Add-In, das ich zuerst 1996 für andere Konvertierungszwecke (HTML, Latex, WinHelp) entwickelt und nun um eine XML-Option erweitert habe. Tools dieser Art sind rar und teuer, außerdem liefern sie gern zu viele oder zu wenige Informationen. Die Performance des Add-Ins bei sehr großen und komplexen Dokumenten lässt zwar zu wünschen übrig, dafür kann ich die Routinen beliebig anpassen und die Bedienung per Mausklick ist auch völlig unkompliziert.
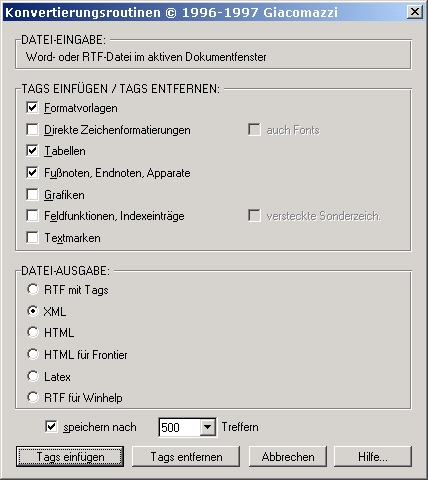
Abb. 3: XML-Konverter für Word
Über die Benutzeroberfläche können bestimmte Informationen, z.B. Formatvorlagen, exportiert und andere Informationen übergangen werden. Auch Word-Spezialitäten wie Sonderzeichen können gerettet werden (s. die ausgeblendete Option "versteckte Sonderzeichen"). Das Werkzeug kommt an der BBAW auch außerhalb der Pilotprojekte, z.B. beim Webmastering, zum Einsatz.
Wie der nachfolgende XML-Auszug zeigt, ist das Konvertierungsprinzip recht einfach: Die Namen der Word-Formatvorlagen werden in XML-Elemente umgewandelt. Ursprünglich wurden die Formatvorlagennamen als Attribute ausgegeben, aber zur leichteren Arbeit in TUSTEP geben wir an dieser Stelle keine Attribute mehr aus; das hat auch den Vorteil, daß das Tagging in überschaubarem Rahmen bleibt. Auch Nicht-Techniker sollten die sachliche Art der Auszeichnung nachvollziehen können.
<?xml version="1.0" encoding='ISO-8859-1'
standalone='yes'?>
<DOKUMENT>
<Sitzung>Nr. <Nr>XXX</Nr> Sitzung des Staatsministeriums
am XX. Monat <Jahr>XXXX</Jahr>.</Sitzung>
<Angaben>Angabe zum Protokoll</Angaben>
<Anwesende>Anwesende bei der Sitzung </Anwesende>
<Weitere_Teilnehmer>Weitere Teilnehmer</Weitere_Teilnehmer>
<Regest><TOP>1.
<TOP><Bearbeitertext>Tagseordnungspunkt; je mit
</Bearbeitertext>Autortext <Bearbeitertext>und Bearbeitertext.
</Bearbeitertext><TOP>2. </TOP><Bearbeitertext>TOP
(...). - Sitzungsnummer und Sitzungsjahr sind zur Generierung der Kopfzeilen
extra ausgezeichnet.</Bearbeitertext></Regest>
</DOKUMENT>
Auf solche XML-Daten greift eine CGI-Anwendung in TUSTEP, die Herr Küster exemplarisch entwickelt hat, fast unmittelbar zurück. Sie ermöglicht die strukturierte Abfrage der Protokolle im Internet mittels eines Webbrowsers. Die Formatvorlagen bzw. XML-Elemente "Jahr", "Anwesende" usw. werden hier als Datenbankfelder ausgelegt:
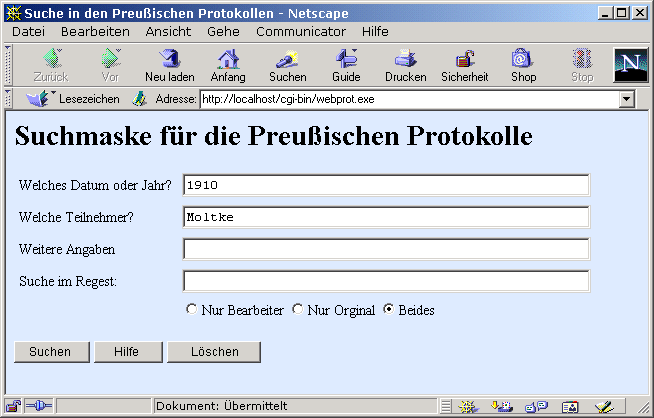
Abb. 4: Suchmaske zum TUSTEP-Makro für die Preußischen Protokolle
Es ist möglich, nur in den wörtlichen Zitaten, nur im Bearbeitertext oder im ganzen Regestentext zu suchen. Die Suchbegriffe erscheinen bei den Treffern rot gefärbt. Die Suche nach dem Sitzungsteilnehmer "Moltke" im Jahr 1910 ergibt z.B. folgendes Ergebnis:
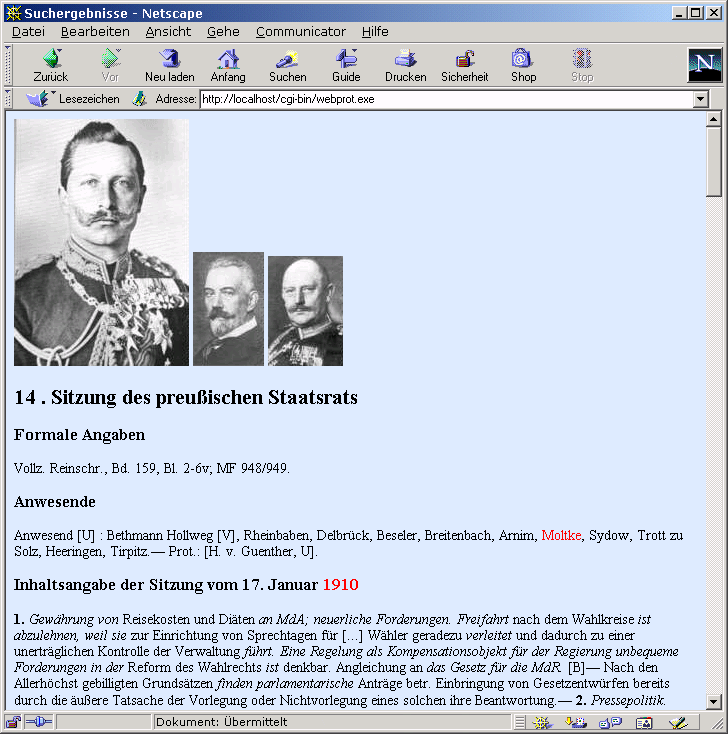
Abb. 5: Von TUSTEP in den XML-Daten ermittelte Treffer
Dennoch schöpft dieser Prototyp weder das Potential der XML-Daten noch das Potential der CGI-Makros in TUSTEP aus. Eine Rolle spielt dabei auch der Plan einer CD-ROM-Veröffentlichung, weshalb bei webprot z.Zt. die Suchfunktionalität, nicht der Lesetext im Vordergrund steht.
Die CD-ROM der Preußischen Protokolle konnte ich mit FolioViews anhand der strukturierten Word-Daten recht schnell entwerfen. FolioViews bietet von Haus aus mehrere Navigationsmöglichkeiten (Views) und eine mächtige Suchengine, außerdem einen guten Word-Import. Das Programm nimmt viel Arbeit ab, ist aber nur in engen Grenzen anpassbar.
Die Druckversion der Protokolle wird im Vorhaben auf der Grundlage des beschriebenen Systems von Formatvorlagen und unter Einsatz eines Makros, das die Kopfzeilen generiert, erstellt.
Beim Schleiermacher-Projekt haben wir uns in erster Linie mit der Textart "Briefe" beschäftigt. Dennoch behandelt das Projekt allgemeine Fragen jeder kritischen Edition:
Solche Anforderungen überfordern gängige Textverarbeitungs- und DTP-Programme, nicht aber die Satzkomponente von TUSTEP. Allerdings kam die Texteingabe mit dem Editor von TUSTEP für die Mitarbeiter der Schleiermacher-Edition nicht in Betracht. Die Positionierung der Apparaten mitten im Grundtext (beim Bezug) macht die tägliche editorische Arbeit im Editor nicht leicht. Das gilt erst recht, wenn folgendes hinzukommt:
Wieder einmal läuft es darauf hinaus, den Eingabekomfort von Word mit Leistungsmerkmalen von TUSTEP zu verbinden. Eine Lösung, die nicht nur einfache Apparate mit Wortbezug abdeckt, kann eine allgemeine Bedeutung für kritische Editionen beanspruchen.
Im Dialog mit der Schleiermacher-Stelle haben wir ein Add-In für die Eingabe der Apparate in Word realisiert. Via XML kommen die Daten zum Satzprogramm von TUSTEP und können dann anforderungsgerecht gesetzt werden. In Word erscheinen die Apparateinträge als Fußnoten mit eigener Zählung plus Metainformationen über Bezugstelle, Typ des Nachweises (Record-Nr oder Seiten-Zeile) u.a.m.
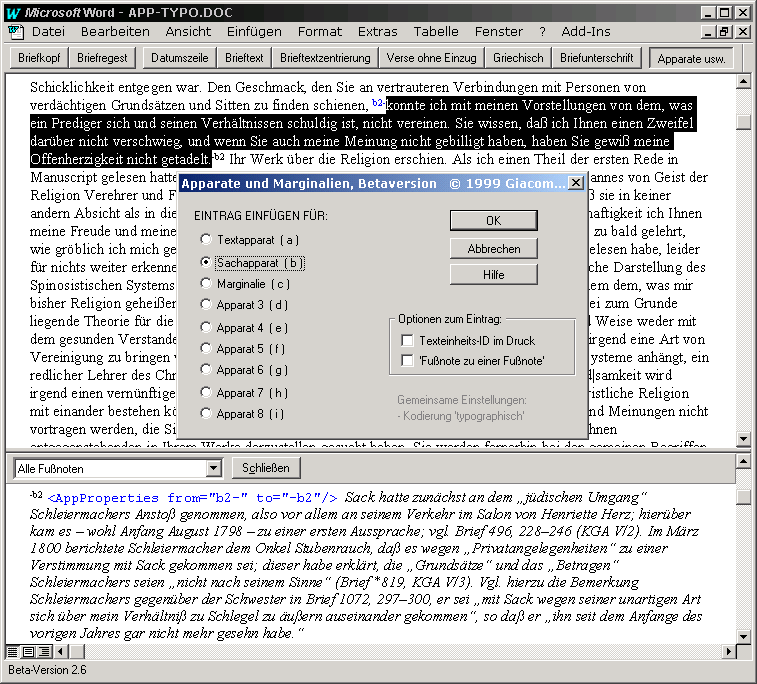
Abb. 6: Add-In für Apparate in Word
Jenseits der Benutzeroberfläche und des sichtbaren Taggings der Metainformationen liegt die Hauptleistung dieses Add-Ins darin, jedem Apparateintrag und seiner Bezugstelle eine einmalige ID zuzuweisen. Bei "b2" (s.o.) steht "b" für den zweiten Apparat, bei Schleiermacher der Sachapparat; der Zähler steht für den einzelnen Eintrag innerhalb des Apparats "b" und wird bei jedem neuen Apparateintrag um eins erhöht. Anders als bei der automatischen Fußnotenzählung in Word bleibt die ID dauerhaft, was auch bei den Korrekturen von großem Vorteil ist. Unverzichtbar sind solche IDs aber für die korrekte Auflösung der überlappenden und verschachtelten Apparate im Satzprogramm. In Word braucht sich der Bearbeiter weder um die Einmaligkeit noch um die Eingabe der ID zu kümmern, beides wird vom Add-In geleistet.
Die aufgezeigte Kodierung der Apparate haben die Herausgeber der Schleiermacher-Edition einem anderen 'xml-artigen' Modell vorgezogen, das ich ebenfalls angeboten hatte und das die Apparate-IDs bereits in Word in der definitiven XML-Auszeichnung verpackte. Jede Fremdkomponente, die den Lesefluß unterbricht, wird von den Editoren als störend empfunden. So wählten wir eine Minimalkodierung, die wir das "typographische Modell" nennen und sich an die MGH-Edition anlehnt.
Zur Weiterverarbeitung werden die Informationen, die das 'typographische
Modell' bereithält, wieder mittels des oben beschriebenen Konverters
nach XML exportiert. Die Apparate werden dabei wie normale Fußnoten
behandelt, sind aber über das ID-Attribut gekennzeichnet; der
Apparatbezug wird durch ein Element AppRefStart und ein Element
FUSSNOTE_Z (das Fußnotenzeichen) explizit gemacht.
<?xml version="1.0" encoding='ISO-8859-1' standalone='yes'?>
<DOKUMENT>
<Briefkopf>(...)</Briefkopf>
<Brieftext>(...) Den Geschmack, den Sie an vertrauteren Verbindungen
mit Personen von verdächtigen Grundsätzen und Sitten zu finden
schienen, <AppRefStart>b2-</AppRefStart>konnte ich mit meinen
Vorstellungen von dem, was ein Prediger sich und seinen Verhältnissen
schuldig ist, nicht vereinen. Sie wissen, daß ich Ihnen einen Zweifel
darüber nicht verschwieg, und wenn Sie auch meine Meinung nicht
gebilligt haben, haben Sie gewiß meine Offenherzigkeit nicht
getadelt.<FUSSNOTE_Z Ref="-b2"/> Ihr Werk über die Religion
erschien. </Brieftext>
(...) <FUSSNOTE Ref="-b2">
<AppProperties from="b2-" to="-b2"/> <i>Sack hatte zunächst
an dem "jüdischen Umgang" Schleiermachers Anstoß genommen, also
vor allem an seinem Verkehr im Salon von Henriette Herz; hierüber kam es
- wohl Anfang August 1798 - zu einer ersten Aussprache; vgl. Brief 496,
228-246 (KGA V/2). Im März 1800 berichtete Schleiermacher dem Onkel
Stubenrauch, daß es wegen "Privatangelegenheiten" zu einer Verstimmung
mit Sack gekommen sei; dieser habe erklärt, die "Grundsätze" und
das "Betragen" Schleiermachers seien "nicht nach seinem Sinne" (Brief *819,
KGA V/3). Vgl. hierzu die Bemerkung Schleiermachers gegenüber der
Schwester in Brief 1072, 297-300, er sei "mit Sack wegen seiner unartigen Art
sich über mein Verhältniß zu Schlegel zu äußern
auseinander gekommen", so daß er "ihn seit dem Anfange des vorigen
Jahres gar nicht mehr gesehn habe."</i>
</FUSSNOTE>
</DOKUMENT>Nach dem Import der XML-Daten in TUSTEP müssen sie an die Konventionen von TUSTEP, insbesondere von AUMBRUCH, angepasst werden. Dazu werden die Apparateinträge zuerst an die Bezugstelle verschoben und unsere IDs in die TUSTEP-Kodierung für Apparate übersetzt. Leider vermag TUSTEP es nicht, XML-Attribute direkt auszuwerten; dort wären ja alle Informationen für den Satz bereits enthalten.

Abb. 7: Satzausgabe von Apparaten mit TUSTEP (Kontrollausdruck)
Das aktuelle Satzergebnis entspricht nicht ganz dem Druckbild eines Schleiermacher-Bandes. Doch der klare Aufbau der Apparate auf der Seite hat bereits einen hohen Gebrauchswert für die tägliche Editionsarbeit. Ein solcher Kontrollausdruck gibt den Mitarbeitern einen guten Eindruck des Endprodukts während der Bearbeitungsphase, nicht erst nach Abschluß der Editionarbeit, und erleichtert sehr die Korrekturarbeit. Nicht zuletzt können solche Ausdrucke auch dazu gebraucht werden, den Fortschritt einer langjährigen Editionsarbeiten gegenüber den Geldgebern zu belegen.
Wir testen z.Zt. ein Batch-Verfahren, das es den Mitarbeitern auch ohne TUSTEP-Kenntnisse erlaubt, solche Kontrollausdrucken auf Tastendruck zu generieren.
Bei den JDG geht es um eine völlig andere Problematik als bei Editionsvorhaben, nämlich um Database Publishing. Diese Publikationsform kann aber ebenfalls gut via XML gemeistert werden. Das vorrangige Ziel dieses Pilotprojekts war die Entwicklung eines Verfahrens zur hausinternen Herstellung des jährlichen Berichtbandes. Dieses Ziel haben wir kürzlich erreicht: Der Berichtsband 1999 wurde komplett via XML mit TUSTEP gesetzt. Die Datenmenge mag als ein Indiz gelten: Titelteil und Registerteil ergeben zusammen ca. 17 MB. Das neue Verfahren hat eine erhebliche Reduzierung der Herstellungskosten zur Folge. Aufgrund der im Haus erstellten Satzproben und Prüfroutinen können außerdem Korrekturen am Manuskript leichter durchgeführt werden, wovon die wissenschaftliche Arbeit und Qualität profitiert. Außerdem eröffnen die XML-Daten ganz neue Perspektiven in Bezug auf die Publikationsformen.
Der große Vorteil von Datenbanken ist ja, daß besondere Vorrichtungen zur Datenstrukturierung entfallen, da das Datenbanksystem sie garantiert. Allerdings eignen sich Datenbanken nur für Daten mit einer starren Struktur. Die Anpassung an neue Anforderungen ist schwer. Zur Erfassung und Verwaltung bibliographischer Daten bei großen Bibliographievorhaben und in Bibliotheken ist das Datenbanksystem allegro-c in Deutschland seit vielen Jahren der Stand der Dinge. Es unterstützt die maßgeblichen bibliographischen Standards, bietet dem Benutzer alle nötigen Funktionen, wird ständig weiterentwickelt auch im regen Austausch auf der Mailingsliste. Daher ist verständlich, daß eine Umstellung auf TUSTEP als Erfassungsinstrument auch beim Vorhaben JDG nicht zur Debatte stand - obwohl TUSTEP sich auch auf bibliographischem Gebiet bewährt hat.
allegro-c verfügt über mächtige Berichts- und
Exportfunktionen so wie fertige Exportfilter. Da ein XML-Export nicht dazu
gehört (auf der Mailingsliste wird aber darüber diskutiert), haben
wir ihn selbst enwickelt, teils mit den allegro-Mitteln, teils mit
Perl. In allegro-c werden die Daten in
die gewünschte Reihenfolge sortiert und gemäß einem
einfachen XML-Tagging exportiert. Anstelle der numerischen Kategorien von
allegro-c setzen wir sprechende Elementnamen, z.B.
<Titel> anstelle von #20; die
Sonderzeichen für osteuropäische Sprachen wandeln wir in
ISO-Entities um; eine minimale DTD zum Parsen wird eingefügt.
Datenbankgestützte Publikationen bestehen wesentlich in der
Konstruktion des zu veröffentlichenden Textes aus den vielen
Datenbankfeldinhalten. Wichtiger Aspekt dabei ist das Einfügen von
Trennern bzw. Verbindungstexten zwischen den einzelnen Feldinhalten. Wir
fügen solche Trenner gemäß den JDG-Richtlinien
kontextabhängig ein, z.B. "-" zwischen den Elementen
<Titel> und <Auflage>, aber "/" wenn
<Hrsg> auf <Titel> folgt. Bei der
Konvertierung wird auch die bibliographische "Systematik"
(Überschriften), ebenfalls automatisch, an die richtigen Stellen in die
XML-Datei eingefügt.
Die Konstruktion des Textes, hier "Titelmontage" genannt, wird schrittweise erledigt, teils schon beim Datenbankexport, zum größten Teil bei der Aufbereitung der XML-Daten mit Perl, und zum Teil in TUSTEP. Diese Arbeitsteilung ist nicht bindend, sondern hängt eher mit der allmählichen Durchdringung der bibliographischen Regeln und typographischen Konventionen der JDG zusammen. Die Titelmontage hätte auch ganz in TUSTEP oder auch ganz ohne TUSTEP erfolgen können. Bei einer Konsolidierung des Gesamtverfahrens wäre der Gesichtspunkt wichtig, daß ein voll konstruierter XML-Text sich jederzeit leicht in anderer Form publizieren läßt; daher sollte die Konstruktion des Textes auf der XML-Ebene erfolgen.
Zur Zeit fallen aber in TUSTEP direkt vor dem Satz zwei Konstruktionsschritte an. Die Sammelbandbeiträge werden "kumuliert", d.h. die endgültigen Nummern der Einzelbeiträge ermittelt und beim Sammelbandtitel ausgegeben ("Enth. auch: ...") und die Sammelband-Nummer bei den einzelnen Beiträgen eingesetzt ("In: ..."). Schließlich wird aus typographischer Sicht eine zusätzliche Klassifizierung der Titelaufnahmen vorgenommen.
TUSTEP unterstützt seit kurzem den Satz von XML-artigen Daten durch
eine Spitzklammerkonvention. In Spitzklammern enthaltene Tags werden eo ipso
als Satzmakros gelesen und verarbeitet. In der Ausgabedatei werden die
Satzmakros durch Satzanweisungen und eventuelle Textteile ersetzt. Hier ist
das mitgelieferte Standard-Makro TAGS eine große Hilfe; es liefert eine
hierarchische Liste aller in einem Quelldokument enthalten Tags samt
Kontext. Damit ist es möglich, die Satzanweisungen nicht einfach 1:1,
sondern unter Berücksichtung des Kontextes zuzuweisen. So wird (s.u.)
ein unterschiedlicher Trenner bei <Titel> vor
<Auflage> und <Hrsg>
zugewiesen.
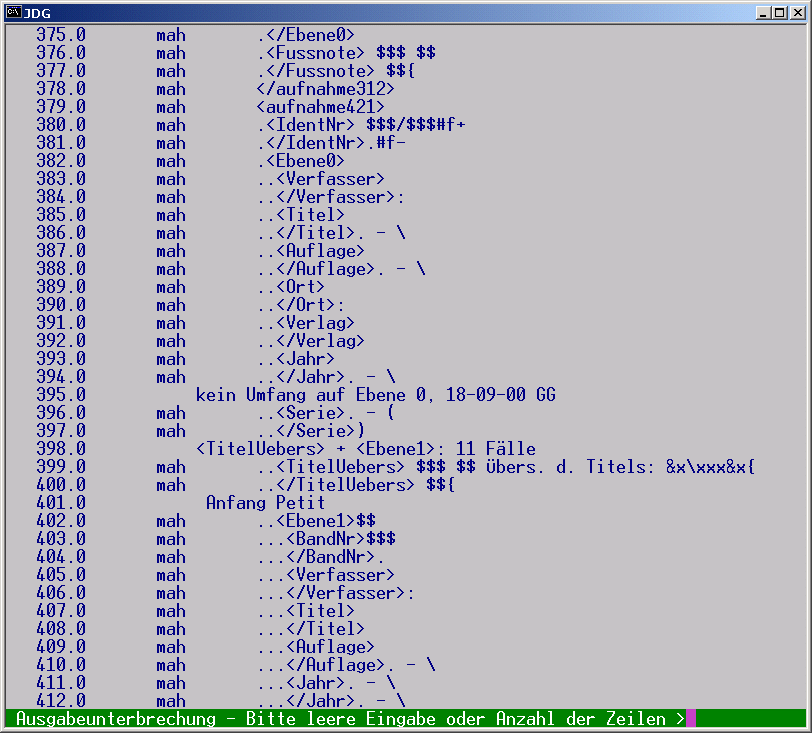
Abb. 8: TAGS-Definitionen für den Satz der JDG (Ausschnitt)
Der abgebildete Ausschnitt der TAGS-Definitionen für die JDG zeigt
den Anfang der Struktur für mehrbändige Monographien
<Aufnahme421>. Auf die einzelnen Start- und Endtags, die
mit TAGS ermittelt werden, folgen die jeweils gewünschten
Satzanweisungen bzw. textlichen Ergänzungen. Bei diesem Aufnahmetyp
kommen fast alle Elemente auf verschiedenen Ebenen vor, da die
Einzelbände eines Werkes ebenfalls einen Titel usw. haben. Die
Ebene0 umklammert den Gesamteintrag, Ebene1 die
Einzelbände, Ebene2 ev. Teilbände. Damit kann dem
Element Titel ein unterschiedliches Format nach Kontext
zugewiesen werden - und zwar ohne daß die Quelldaten manuell
geändert zu werden brauchen. Da die Einzelbände bei JDG in kleiner
Schrift gesetzt werden sollen, genügt es (s.o.) die Satzanweisung
für petit-Anfang $$ dem Starttag
<Ebene1> und die für petit-Ende $${ dem
Endtag </Ebene1> zuzuweisen. Die Erscheinung von
$$-Teilen wird a.a.O. festgelegt. Folgendes Beispiel zeigt etwas
von einem mehrbändigen Werk (1040.), von Sammelbandbeiträgen
(1048.) und von der "Systematik" (A-Überschriften):

Abb. 9: Satzausgabe für JDG
Analog dazu habe ich das Satzprogramm für die umfangreichen Register erstellt. Nach dem hier gezeigten Prinzip möchten wir generell XML-Daten mit TUSTEP setzen.
Die Konstruktion des kompletten Lesetexts in XML bietet ganz neue Publikationsmöglichkeiten. Die XML-Daten können unmittelbar als HTML im Internet präsentiert werden, indem sie mit einem Stylesheet verbunden werden. Einige Tests liegen auf der JDG-Homepage. Gebrauchswert hat aber nicht nur der Lesetext, sondern auch der direkte Zugriff auf strukturierte Daten, die der Benutzer z.B. in eigene Bibliographien importieren kann.
Aus Zeitmangel nur ein paar Notizen.
Ein wichtiger Nebenaspekt ist der Antrag auf Übernahme von Sonderzeichen der Mediävistik in den Unicode-Standard, den ich aus Anlaß einer elektronischen Publikation bei der MGH-Stelle angeregt habe und der jetzt nach Einbeziehung mehrerer Fachinstanzen offiziell beim Unicode Consortium eingereicht worden ist.
Technisch interessant ist der Datenaustausch zwischen XML und relationaler Datenbank, und zwar in beiden Richtungen. Das hat aber nicht mit TUSTEP zu tun.
Ein weites Feld. Siehe immerhin:
Giacomazzi, Giorgio: Anmerkungen zu EDV und
Editionen am Beispiel der MEGA,
In: MEGA-Studien 1999, hrsg. von der Internationalen Marx-Engels-Stiftung,
Amsterdam 2002, 26-33.
TUSTEP kommt dem Grundansatz der Pilotprojekte sehr entgegen. Die Pilotprojekte basieren auf der Idee der "wohlgeformten Daten". Es wird mit Datenstrukturen experimentiert, die nicht zu Beginn feststehen. Eine DTD steht bei uns nicht am Anfang, sondern am Ende, als Ergebnis oder "Abfallprodukt" eines erfolgreichen Migrationsprozesses. TUSTEP bietet uns Werkzeuge, die vor, beim und auch nach eine Publikation Eingriff und Korrekturen an diesen Datenstrukturen ermöglichen. Das hat die erfolgreiche Zusammenarbeit begründet.
Allerdings gehen aus den Projekten auch Verbesserungswünsche an TUSTEP hervor.
1. TUSTEP unterstützt erst teilweise XML, indem es Elementnamen als Satzmakros liest. XML-Attribute werden nicht unterstützt, und das machte sich bei den Apparaten, wo wir mit ID-Attributen operieren, bemerkbar. Die praktische Handhabung hierarchischer Satzmakros ist auch nicht immer ganz einfach.
2. Das Satzprogramm unterstützt standardmäßig nur die seitenweise Zeilennumerierung und deren Auswertung in Querverweisen. Prof. Ott hat uns aber zugesagt, eine Funktion zur leichteren Handhabung der doch verbreiteten abschnittsweisen Zeilennumerierung zu implementieren.
[1] http://www.itug.de.
Dem Vortrag gingen Beiträge von Dr. Johannes Thomassen ("Jahresberichte
für Deutsche Geschichte") und Dr. Wolfgang Virmond ("Schleiermacher -
Kritische Gesamtausgabe") voraus, die über die EDV-Anforderungen und
über Erfahrungen in den Pilotprojekten aus der Sicht der
wissenschaftlichen Mitarbeiter und Vorhaben berichteten. Der Werdegang der
Pilotprojekte ist im "Circular" der BBAW dokumentiert.
[2] Jannidis' Vortrag basierte auf einem Aufsatz in der Fachzeitschrift "editio", der eine wichtige Rolle für meine Arbeit und die Konzeption der Pilotprojekte gespielt hat. Vgl. Jannidis, Fotis: Wider das Altern elektronischer Texte. Philologische Textauszeichnung mit TEI, in: editio 11 (1997), S. 152-177.
Vier Jahre später hat sich XML definitiv durchgesetzt. Überzeugungsarbeit ist nicht mehr nötig, eher gibt es zu viel XML, nützliche Tools sind verfügbar, und selbst hat man auch dazu gelernt. In manchen Punkten würde ich anders vorgehen, doch der Grundansatz der Pilotprojekte scheint nach wie vor aktuell zu sein. Es ist auch nicht sicher, daß die inzwischen gängigen XML-Editoren die Eingabeproblematik bei dieser Art von Texten befriedigend lösen bzw. ob die Programmierbarkeit von Word am Ende die besseren Karten gibt. Diese Alternative war eine unter mehreren zu klärenden Fragen, die ich in einem DFG-Antrag bei der BBAW hinterlassen hatte.
Leider nicht viel besser geworden ist die Lage um TUSTEP. Die Projekte 1999/2000 hatten nicht nur für die BBAW eine Pilotfunktion, sondern aus Sicht eines Teils des damaligen Mitarbeiterstamms auch für TUSTEP selbst. Deshalb kam die Kooperation zustande. Die Öffnung auf eine heterogene EDV-Landschaft hin endete aber in mehrerer Hinsicht. Diese Projekte wurden "vergessen". (Zur Erfurter Jahrestagung s. den Tagungsbericht und TUSTEP nach 2002). Bei der Neubeschäftigung mit TUSTEP Anfang dieses Jahres bin ich auf eine Haltung gestoßen, die selbst den Sinn offener Schnittstellen in Frage stellt, doch auch auf unerwartete Zustimmung. Ein Produkt dieser neuen Auseinandersetzung ist "Ein kleines NUMMERIERE in Python".
Zugleich ist die TUSTEP-Konkurrenz stärker geworden.